
Today we're going to learn how to build a system to ask ChatGPT questions and get accurate answers about your documentation. The whole project we are going to build is available here (opens in a new tab). You can also try an interactive version at https://docs.embedbase.xyz (opens in a new tab).
Overview

We're going to cover a few things here, but the big picture is that:
- We'll need to store our content in a database
- We'll get the user to type a query
- We'll search the database for the results that are most similar to the user query (more on that later)
- We'll create a "context" based on the top 5 most similar results matching the query and ask ChatGPT:
Answer the question based on the context below, and if the question can't be answered based on the context, say "I don't know"
Context: [CONTEXT]
---
Question: [QUESTION]
Answer:
Diving into the implementation
Alright let's get started
Here's what you'll be needing for this tutorial
- Embedbase api key (opens in a new tab), a database that allows you to find "most similar results". Not all databases are suited for this kind of job. Today we'll be using Embedbase which allows you to do just that. Embedbase allows you to find "semantic similarity" between a search query and stored content.
- OpenAI api key (opens in a new tab): that's for the ChatGPT part.
- Nextra (opens in a new tab): NodeJS installed (opens in a new tab).
Write the Embedbase and OpenAI API keys in .env:
OPENAI_API_KEY="<YOUR KEY>"
EMBEDBASE_API_KEY="<YOUR KEY>"As a reminder, we will create a QA documentation powered by ChatGPT with the amazing documentation framework Nextra (opens in a new tab) which allows you to write documentation using NextJS, tailwindcss and MDX (Markdown + React). We will also use Embedbase (opens in a new tab) as a database and OpenAI (opens in a new tab) to use ChatGPT.
Creating a Nextra doc
You can find and use the official Nextra documentation template here (opens in a new tab). Once you have created your documentation with this template, open it with your favorite editor.
# we won't use "pnpm" here, rather the traditional "npm"
rm pnpm-lock.yaml
npm i
npm run devNow just head to https://localhost:3000 (opens in a new tab).
Try to edit some of the .mdx documents and see the content changing.
Preparing and storing the documents
The first step requires us to store our documentation in Embedbase. There's a small caveat, though, this works better if we store relatively small chunks in the DB. We'll chunk our text by sentences. Let's start by writing a script called sync.js in the folder scripts.
You'll need the glob library to list files npm i glob@8.1.0 (we'll use the 8.1.0 version).
const glob = require('glob')
const fs = require('fs')
const sync = async () => {
// 1. read all files under pages/* with .mdx extension
// for each file, read the content
const documents = glob.sync('pages/**/*.mdx').map(path => ({
// we use as id /{pagename} which could be useful to
// provide links in the UI
id: path
.replace('pages/', '/')
.replace('index.mdx', '')
.replace('.mdx', ''),
// content of the file
data: fs.readFileSync(path, 'utf-8')
}))
// 2. here we split the documents in chunks, you can do it in many different ways, pick the one you prefer
// split documents into chunks of 100 lines
const chunks = []
documents.forEach(document => {
const lines = document.data.split('\n')
const chunkSize = 100
for (let i = 0; i < lines.length; i += chunkSize) {
const chunk = lines.slice(i, i + chunkSize).join('\n')
chunks.push({
// and use id like path/chunkIndex
id: document.id + '/' + i,
data: chunk
})
}
})
}
sync()Now that we have our chunks we need to store them in a DB, we'll extend our script so that it adds the chunks to Embedbase.
To query Embedbase, we'll install the version 2.6.9 of node-fetch by running npm i node-fetch@2.6.9.
const fetch = require('node-fetch')
// your Embedbase api key
const apiKey = process.env.EMBEDBASE_API_KEY
const sync = async () => {
// ...
// 3. we then insert the data in Embedbase
const response = await fetch(
'https://embedbase-hosted-usx5gpslaq-uc.a.run.app/v1/documentation',
{
// "documentation" is your dataset ID
method: 'POST',
headers: {
Authorization: 'Bearer ' + apiKey,
'Content-Type': 'application/json'
},
body: JSON.stringify({
documents: chunks
})
}
)
const data = await response.json()
console.log(data)
}
sync()Great, you can run it now
EMBEDBASE_API_KEY="<YOUR API KEY>" node scripts/sync.jsIf it worked well you should be seeing:

Getting the user's query
Now, we will modify the Nextra documentation theme to replace the built-in search bar with one that will be ChatGPT-powered.
We'll add a Modal component to theme.config.tsx with the following content:
// update the imports
import { DocsThemeConfig, useTheme } from 'nextra-theme-docs'
const Modal = ({ children, open, onClose }) => {
const theme = useTheme()
if (!open) return null
return (
<div
style={{
position: 'fixed',
top: 0,
left: 0,
right: 0,
bottom: 0,
backgroundColor: 'rgba(0,0,0,0.5)',
zIndex: 100
}}
onClick={onClose}
>
<div
style={{
position: 'absolute',
top: '50%',
left: '50%',
transform: 'translate(-50%, -50%)',
backgroundColor: theme.resolvedTheme === 'dark' ? '#1a1a1a' : 'white',
padding: 20,
borderRadius: 5,
width: '80%',
maxWidth: 700,
maxHeight: '80%',
overflow: 'auto'
}}
onClick={e => e.stopPropagation()}
>
{children}
</div>
</div>
)
}Now we want to create the search bar:
// update the imports
import React, { useState } from 'react'
// we create a Search component
const Search = () => {
const [open, setOpen] = useState(false)
const [question, setQuestion] = useState('')
// ...
// All the logic that we will see later
const answerQuestion = () => {}
// ...
return (
<>
<input
placeholder="Ask a question"
// We open the modal here
// to let the user ask a question
onClick={() => setOpen(true)}
type="text"
/>
<Modal open={open} onClose={() => setOpen(false)}>
<form onSubmit={answerQuestion} className="nx-flex nx-gap-3">
<input
placeholder="Ask a question"
type="text"
value={question}
onChange={e => setQuestion(e.target.value)}
/>
<button type="submit">Ask</button>
</form>
</Modal>
</>
)
}Last, update the config to set the search bar we created:
const config: DocsThemeConfig = {
logo: <span>My Project</span>,
project: {
link: 'https://github.com/shuding/nextra-docs-template'
},
chat: {
link: 'https://discord.com'
},
docsRepositoryBase: 'https://github.com/shuding/nextra-docs-template',
footer: {
text: 'Nextra Docs Template'
},
// add this to use our Search component
search: {
component: <Search />
}
}Building the context
Here you will need the OpenAI token counting library tiktoken so run npm i @dqbd/tiktoken.
Now we are going to build the prompt to contextualise ChatGPT in a NextJS API endpoint.
Create a file pages/api/buildPrompt.ts with the code:
// pages/api/buildPrompt.ts
import { get_encoding } from '@dqbd/tiktoken'
// Load the tokenizer which is designed to work with the embedding model
const enc = get_encoding('cl100k_base')
const apiKey = process.env.EMBEDBASE_API_KEY
// this is how you search Embedbase with a string query
const search = async (query: string) => {
return fetch(
'https://embedbase-hosted-usx5gpslaq-uc.a.run.app/v1/documentation/search',
{
method: 'POST',
headers: {
Authorization: 'Bearer ' + apiKey,
'Content-Type': 'application/json'
},
body: JSON.stringify({
query: query
})
}
).then(response => response.json())
}
const createContext = async (question: string, maxLen = 1800) => {
// get the similar data to our query from the database
const searchResponse = await search(question)
let curLen = 0
const returns = []
// We want to add context to some limit of length (tokens)
// because usually LLM have limited input size
for (const similarity of searchResponse['similarities']) {
const sentence = similarity['data']
// count the tokens
const nTokens = enc.encode(sentence).length
// a token is roughly 4 characters, to learn more
// https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
curLen += nTokens + 4
if (curLen > maxLen) {
break
}
returns.push(sentence)
}
// we join the entries we found with a separator to show it's different
return returns.join('\n\n###\n\n')
}
// this is the endpoint that returns an answer to the client
export default async function buildPrompt(req, res) {
const prompt = req.body.prompt
const context = await createContext(prompt)
const newPrompt = `Answer the question based on the context below, and if the question can't be answered based on the context, say "I don't know"\n\nContext: ${context}\n\n---\n\nQuestion: ${prompt}\nAnswer:`
res.status(200).json({ prompt: newPrompt })
}Making calls to ChatGPT
First add some utility function that is used to make stream calls to OpenAI in the file utils/OpenAIStream.ts, you'll need to install eventsource-parser by running npm i eventsource-parser.
import {
createParser,
ParsedEvent,
ReconnectInterval
} from 'eventsource-parser'
export interface OpenAIStreamPayload {
model: string
// this is a list of messages to give ChatGPT
messages: { role: 'user'; content: string }[]
stream: boolean
}
export async function OpenAIStream(payload: OpenAIStreamPayload) {
const encoder = new TextEncoder()
const decoder = new TextDecoder()
let counter = 0
const res = await fetch('https://api.openai.com/v1/chat/completions', {
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${process.env.OPENAI_API_KEY ?? ''}`
},
method: 'POST',
body: JSON.stringify(payload)
})
const stream = new ReadableStream({
async start(controller) {
// callback
function onParse(event: ParsedEvent | ReconnectInterval) {
if (event.type === 'event') {
const data = event.data
// https://beta.openai.com/docs/api-reference/completions/create#completions/create-stream
if (data === '[DONE]') {
controller.close()
return
}
try {
const json = JSON.parse(data)
// get the text response from ChatGPT
const text = json.choices[0]?.delta?.content
if (!text) return
if (counter < 2 && (text.match(/\n/) || []).length) {
// this is a prefix character (i.e., "\n\n"), do nothing
return
}
const queue = encoder.encode(text)
controller.enqueue(queue)
counter++
} catch (e) {
// maybe parse error
controller.error(e)
}
}
}
// stream response (SSE) from OpenAI may be fragmented into multiple chunks
// this ensures we properly read chunks and invoke an event for each SSE event stream
const parser = createParser(onParse)
// https://web.dev/streams/#asynchronous-iteration
for await (const chunk of res.body as any) {
parser.feed(decoder.decode(chunk))
}
}
})
return stream
}Then create a file pages/api/qa.ts which will be an endpoint to simply make a streaming call to ChatGPT.
// pages/api/qa.ts
import { OpenAIStream, OpenAIStreamPayload } from '../../utils/OpenAIStream'
export const config = {
// We are using Vercel edge function for this endpoint
runtime: 'edge'
}
interface RequestPayload {
prompt: string
}
const handler = async (req: Request, res: Response): Promise<Response> => {
const { prompt } = (await req.json()) as RequestPayload
if (!prompt) {
return new Response('No prompt in the request', { status: 400 })
}
const payload: OpenAIStreamPayload = {
model: 'gpt-3.5-turbo',
messages: [{ role: 'user', content: prompt }],
stream: true
}
const stream = await OpenAIStream(payload)
return new Response(stream)
}
export default handlerConnect everything & Asking questions
Now it is time to ask questions through API calls.
Edit theme.config.tsx to add the function to the Search component:
// theme.config.tsx
const Search = () => {
const [open, setOpen] = useState(false)
const [question, setQuestion] = useState('')
const [answer, setAnswer] = useState('')
const answerQuestion = async (e: any) => {
e.preventDefault()
setAnswer('')
// build the contextualized prompt
const promptResponse = await fetch('/api/buildPrompt', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
prompt: question
})
})
const promptData = await promptResponse.json()
// send it to ChatGPT
const response = await fetch('/api/qa', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
prompt: promptData.prompt
})
})
if (!response.ok) {
throw new Error(response.statusText)
}
const data = response.body
if (!data) {
return
}
const reader = data.getReader()
const decoder = new TextDecoder()
let done = false
// read the streaming ChatGPT answer
while (!done) {
const { value, done: doneReading } = await reader.read()
done = doneReading
const chunkValue = decoder.decode(value)
// update our interface with the answer
setAnswer(prev => prev + chunkValue)
}
}
return (
<>
<input
placeholder="Ask a question"
onClick={() => setOpen(true)}
type="text"
/>
<Modal open={open} onClose={() => setOpen(false)}>
<form onSubmit={answerQuestion} className="nx-flex nx-gap-3">
<input
placeholder="Ask a question"
type="text"
value={question}
onChange={e => setQuestion(e.target.value)}
/>
<button type="submit">Ask</button>
</form>
<p>{answer}</p>
</Modal>
</>
)
}You should have this by now:

Of course, feel free to improve the style 😁.
Closing thoughts
In summary, we have:
- Created a Nextra documentation
- Prepared and store our documents in Embedbase
- Built an interface to get the user's query
- Searched for the context of the question in our database to provide ChatGPT
- Built the prompt with this context and call ChatGPT
- Let the user ask a question by connecting everything together
Thank you for reading this document, there is an open-source template to create this type of documentation here (opens in a new tab).
If you liked this blog post, leave a star ⭐️ on https://github.com/different-ai/embedbase (opens in a new tab), we are also eager for feedback ❤️. If you want to self-host it, please book a demo (opens in a new tab) 😁. Please feel free to contact us for any help!
Further reading
Embeddings are a machine learning concept that allows you to represent the semantics of your data as a number, which allows you to create features such as:
- semantic search (e.g., what is the similarity between "the cow eats grass" and "the monkey eats bananas", which also works for comparing images, etc.)
- recommendation systems (if you like the movie Avatar, you might like Star Wars)
- classification ("this movie is amazing" is a positive sentence, "this movie sucks" is a negative sentence)
- generative search (chat bot that answers questions about a pdf, a website, a youtube video, etc.)
Embeddings are not a new technology, but they have been made more popular, more general and more accessible recently thanks to the OpenAI embeddings endpoint which is fast and cheap. We won't dive into the technical subject of embeddings, there is a lot of information about them on the internet.
AI embeddings can be thought of as a sorting hat of Harry Potter. Just like the sorting hat assigns houses based on the traits of the students, AI embeddings are assigned to similar content based on their features. When we want to find similar items, we can ask AI to provide us with embeddings of the items, and then calculate the distance between them. The closer the distance between the embeddings, the more similar the items. This process is similar to how the sorting hat uses the traits of each student to determine their best fit for a house. By using AI embeddings, we can quickly and easily compare items based on their features, resulting in smarter decisions and more efficient search results.
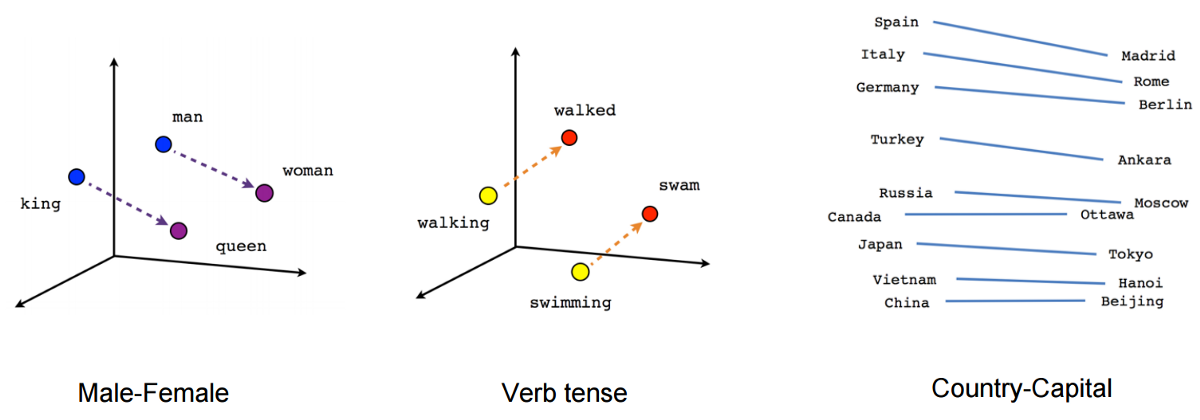
The method described above is simply to embed words, but today, sentences, images, sentences + images and many other things are possible.
When you want to use embeddings in a production software, there are some pitfalls to be careful with:
- All the infra of storing embeddings at scale
- Cost optimization (e.g. avoid calculating a data twice)
- Segmentation of user embeddings (you don't want your search function to display another user's data)
- Dealing with the model input size limit
- Integration with popular app infras (supabase, firebase, google cloud, etc.)
Preparing the data continuously in GitHub Actions
The point of embeddings is to be able to index any kind of unstructured data, we want our documentation to be indexed every time we modify it, right? This is a GitHub action that will index every markdown file when a git push is done on the main branch:
# .github/workflows/index.yaml
name: Index documentation
on:
push:
branches:
- main
jobs:
index:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: actions/setup-node@v2
with:
node-version: 14
- run: npm install
- run: node scripts/sync.js
env:
EMBEDBASE_API_KEY: ${{ secrets.EMBEDBASE_API_KEY }}Don't forget to add EMBEDBASE_API_KEY to your GitHub secrets (opens in a new tab).